Blogs
The beginning of my jupyter notebook.
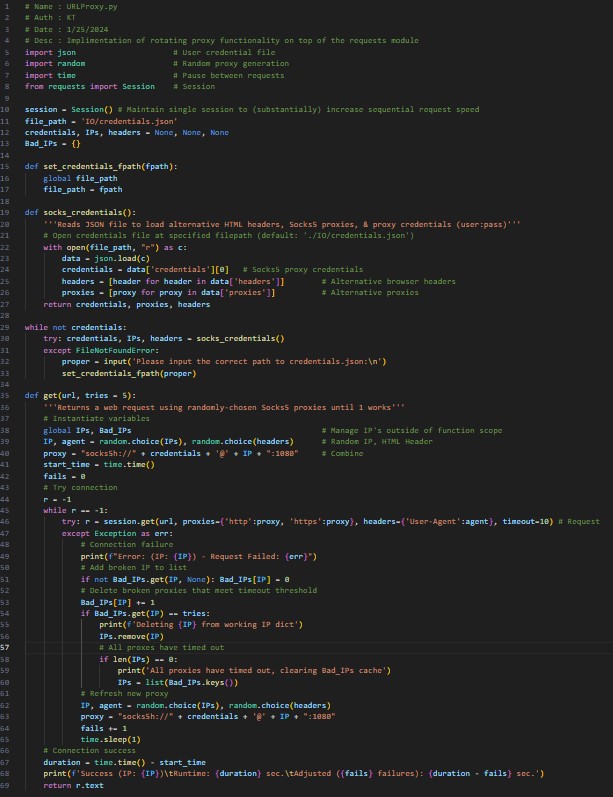
URLProxy module (<60 lines of code).

Current iteration of NBA-Vis.
When I began writing NBA-Vis, my intended goal differed greatly from the current revision. This was my first major project (>1 months of coding). My original intention was to create data visualizations for NBA data; I did not plan nor have direction for what the final product would look, I just wanted to produce something tangible. I did not expect to create software libraries, host a webpage, nor a full-fledged database. First I found a data source: a .csv dataset featuring the season averages of all current players.
To keep track of my progress, I began development with a jupyter .ipynb notebook. Normally, these are used for lightweight projects to quickly write small code and conduct small analysis. My desire to quickly create a tangible product meant I wanted to rush into making visuals/graphs, which Jupyter is perfect for. Once I wanted more than a single season's average, I began writing code to web-scrape the data from basketball-reference since it had the most comprehensive amount of data. The code was getting very long.
After I developed working functions to extract team/player data, I wanted to save my data. Before databases, there was Pickle. That's right, I used Pickles to store my data. Pickle objects, specifically, which are data files created from the object serialization python library, Pickle. Do not judge, I had not learned about databases and thought an object-oriented data implimentation may be helpful, especially if I chose to create a client-side desktop program (by this point I had still not decided what final product I wanted). However soon, the project was getting so large that I was forced to make design decisions that I did not think of earlier, such as finding a more feasible and scalable database design; I knew SQL but had never hosted a database, so I chose what was easiest and used a local SQLite installation.
One issue I encountered was that web-scraping basketball-reference proved to be more difficult than I planned. The domain uses rate-limiting to throttle repeated requests from the same client, meaning if I was trying to retrieve lots of data at once (e.g., create a database), the server would reject my connections after a few successful ones. Because I already have a VPN for my entirely legal personal schennanigans, I tried use it to alter my client connection, but this would only temporarily avoid the block: I needed a solid solution.
After seeing a VPN connection could temporarily bypass the block, I knew IP's were logged. My VPN service came with proxy servers that alter your client IP, so I tried plugging that information into the Python 'requests' library to see if that would work without a VPN connection running on my entire machine. Success! But only temporarily. A single proxy would work like a non-proxy connection, it would retrieve a few players data and then the connection would reject. Changing the proxy worked the first few times, but soon even the 1st connection of a new proxy would fail. Something other than IP's must have been logged. Google and StackOverflow suggested changing the browser headers bundled with the connection, something I had seldom familiarity with, however that proved to be the solution I needed. Viola! Add in some for loops to randomize the proxy and browser header meant no two connections would look similar. Kareem 1 - Basketball reference 0.
Soon thereafter, I realized if I wanted to do any solid analytics/visualization work, I would need a robust and comprehensive database that could help me find any insight. More of my time became dedicated to data-engineering, as I needed to think through how to acquire (build db) and retrieve (read db) all necessary data. Would I send SQL queries manually? Build the database as necessary? Have functions with pre-set SQL data retrievals? Utilize an online API? This was the second major design flaw/decision I encountered as a result from poor preparation. I chose to comprehensively build my database, use a robust solution (mySQL) that supports many features, and web-host online to also offer an API. Two major new skills I acquired were Flask and Docker, which I enjoyed learning. These design choices remain in the current iteration of NBA-Vis.
NBA-Vis is my oldest major project. The code, design, and purpose of the program have changed drastically and evolved over time. Starting this project early in my undergrad, I realized it would be beneficial to slow down, not rush development, and wait for myself to acquire new skills necessary to make this a solid product instead of wasting time with Pickles. My recent development has been allocated towards making the web-scraping portion of my code a separate module/library so that others can use it. My first iteration was a very lightweight Python library named 'URLProxy', however I also wanted to develop new skills and improve my software engineering; I spent a few months afterwards writing the same library in C++, mostly to gain experience developing in that language, gaining familiarity with their libraries, cross-platform development, and compilation. NBA-Vis was a great learning experience because I picked up many new tools, but also because of the technical and design challenges that showed me first-hand the importance of proper planning, foresight, and design.

The system requirements.
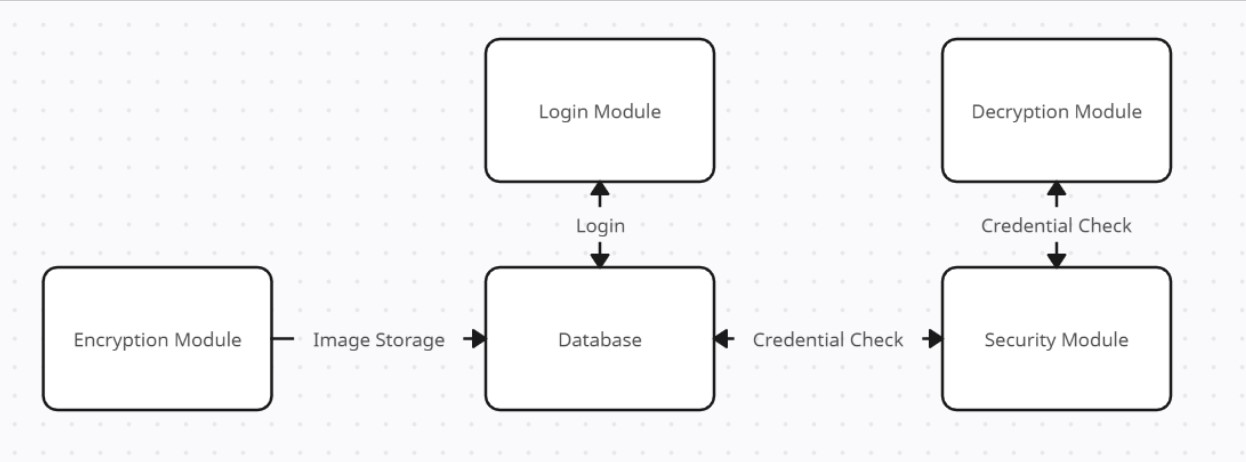
The software design.
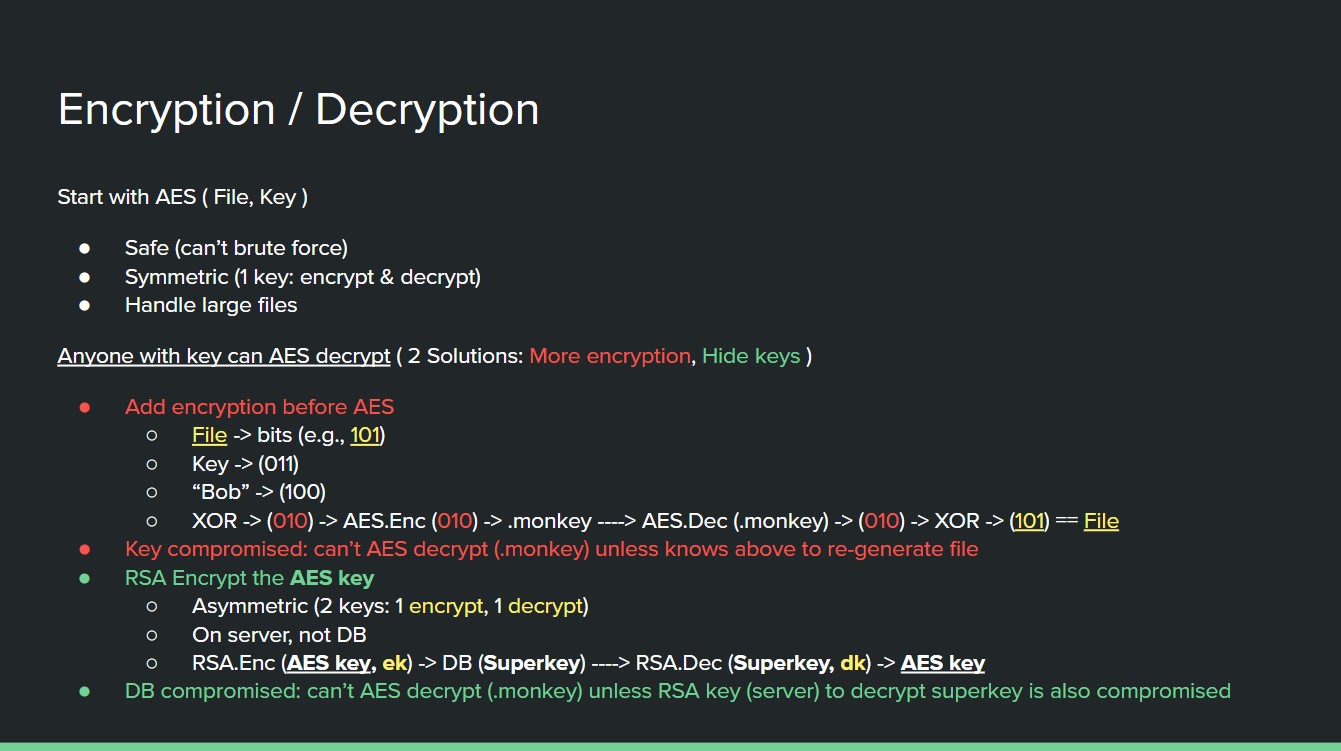
Encryption Scheme.

Current iteration of PIPE.

Encryption page.
PIPE is a web-application that can encrypt / decrypt images based on a user key. Our team name was Marks Monkeys, so we created .MONKEY encrypted files. Unlike other projects, PIPE had a fixed timeline because my partner and I completed it for our software engineering final. Many aspects of PIPE make me proud to this day.
First, my partner and I worked as a two-person group when the standard size was five; our class had a few students drop midway, so our class size left us in a small group. Other groups continued development on their first project, but we wanted to create a new application that incorporated encryption. Our excitement behind the product inspired stronger collaboration and made it easier to assume multiple roles. Reflecting on our recently prior experience completing a large group project, our primary focus was on design instead of code.
Coming from a background with more encryption familiarity (other coursework, cybersecurity club, self study), I took over backend development while my partner did a great job with the frontend and framework. My role was to complete modules for Login, Encryption, Decryption, Security, and if we had time, Testing.
The Login module handled communicating with the security module to authorize user functionality; this incorporated hashing, performing login attempts, registering new accounts, checking for user existence, and retrieval of cookies keys. The security module actually performed these operations by communicating with the database, alongside other functions such as encryption/decryption, database CRUD (create, read, update, delete), RSA key generation/retrieval, and UUID key generation.
Encryption was built ground up using our custom scheme. I started with AES as a base because it is robust: AES can encrypt large files and is symmetric, meaning one user key can be used for encryption/decryption (simple for users). Before performing this AES, I scrambled the file via an XOR operation (symmetric) on the file itself and a static secret key (in our code). If a perpetrator acquired the encrypted file and the user AES key, performing AES decryption would simply return the scrambled file (which would still need an XOR operation with our new secret key). This ensured a user would be required to create an account/use our platform to decrypt (While the AES key is defined by the encryptor, the secret key is ours meaning we can/did limit decryption to only users the encryptor validated). The secret key forces decryptors to use the platform, the user-validation checks ensure only the right ones can decrypt.
We could have designed a tool that stored no information in a database (a simple encryption/decryption program with files and inputted keys), but projects requirements forced us to use one. As such, we did not want to store the AES user key or any other unnecessary information in the database incase the database was somehow compromised (time constraints meant we did not have the ability to sanitize for more advanced threats such as SQL injection). To keep keys safe, we used asymmetric RSA encryption on the AES user key to a create a new 'superkey', which is the one we stored in the database. If anyone compromised our database, they would only find encrypted superkeys; they would need to compromise our server for the asymmetric RSA keys.
User authentication was another constraint: we needed a login system with functioning access-control. As aforementioned, our secret key meant users must use our platform to access decrypting that layer of the encrypted file. We did not want unauthorized users to access file decryption (e.g., if Alice sends Bob an encrypted file A with key A and Charlie got ahold of both the file/key, we wanted to restrict Charlie from making an account and decrypting by uploading that file and key). My solution was to make the encryptor (Alice) specify valid decryption users (Bob) so that only Bob can use our site to decrypt (If Charlie tried it would fail). Now Charlie cannot decrypt Alice's file even if he knows the key.
The last issue we faced was file replication/spoofing. Using the prior Alice/Bob example, if Charlie realizes he does not have permission to decrypt file A, he can encrypt a different image (we'll call it File X) with the same key A and send it to his other account, Dave. Then, he can log into the Dave account. If he tries to decrypt Alice's File A with Key A, it will rightfully fail. The Dave account can only decrypt file X, which is no use to Charlie. However, if he copies File A's encrypted contents into a new file (e.g., File B), renames it to File X, then tries to decrypt using key A, it will work and return the unencrypted contents of Alice's file A. We realized that we had to check the encrypted files to make sure they are originals and unmodified, which meant we must either randomize and store the encrypted name or store the hashed contents of the file. We chose to store the encrypted file name, however storing a hash of the file contents would be a better choice. Storing the encrypted file name can prevent the above scenario if the perpetrator has the file contents/key but lacks the encrypted file name, however if they have the file contents, they likely have access to the encrypted file and can read its name. Storing the hashed file contents would be a better solution because even if Charlie tries to decrypt File X that contains encrypted File A contents, the system would simply see that File X's new contents do not match its original contents when Charlie first uploaded the blank File X.
There were a lot of design and implimentation decisions that we could have done better. However, given the time and personnel constraints, I am proud of the product my partner and I created. Working with encryption always fascinates me! Despite focusing more on planning and design, I learned that I could be more thorough in design details and system requirements. PIPE is still my favorite and coolest project.
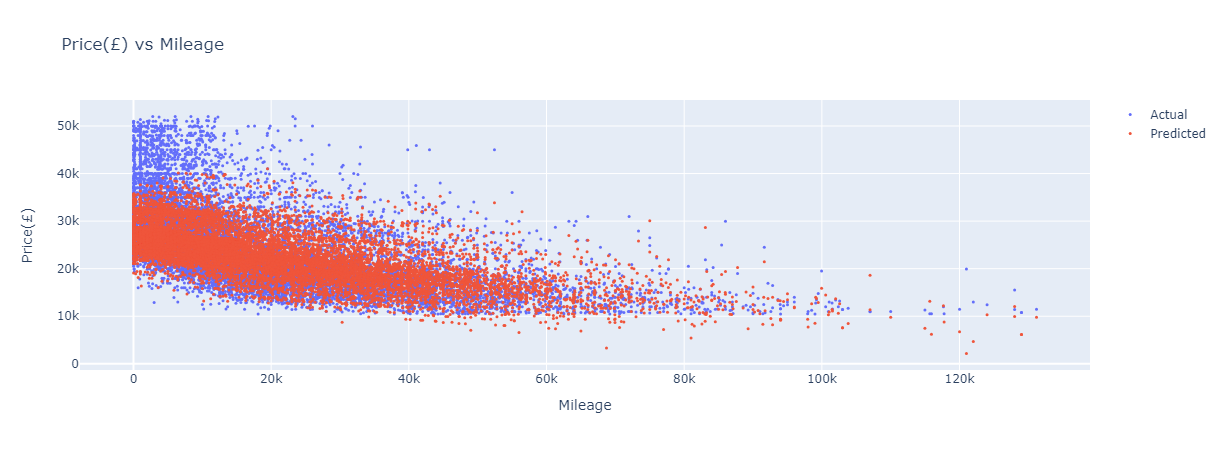
Price vs Mileage Graph.
Price-predictor differs from my other projects in that it is an analytics project, not an engineered piece of complex software. Price-predictor was also a class assignment for my Machine Learning class in Data Science, however this project was the only to give students complete flexibility as to the direction, method, and data they chose. I chose cars because they are cool. And pretty straightforward. Mostly cool though. Unlike my other projects, this was a much smaller timeline (2-3 weeks).
First I needed to choose the proper model to apply to the data. Proper data science requires analyzing the features, characteristics, and desired values of the data to understand which statistical methods could/should be applied. For instance, I would not use an algorithm that is meant to estimate a numerical value if my data lacked numerical values and only contained information about classes (such as a car brand or color). This makes sense: if I had a list of 10 ford cars, 5 of them blue trucks and 5 red sedans, then upon seeing a new sedan, I could probably guess it is red; I could not guess that the sedan costs $20,000 because my data lacks pricing information. Numerical vs class information (regression vs. classification) is one of many data properties that must be considered during model selection.
The dataset I chose was a Kaggle dataset of used cars in the UK with over 100,000 rows. The dataset itself was split into 11 .csv files, each for a different brand (9 brands, 9 features).
Brands include:
- Audi
- BMW
- Ford
- Ford (Focus only)
- Hyundai
- Mercedes
- Mercedes (C-class only)
- Skoda
- Toyota
- Vauxhall
- Volkswagen
Dataset features include:
- Model
- Year
- Price (Euros)
- Transmission
- Mileage
- Fuel Type
- Road Tax (Euros)
- MPG
- Engine Size
(Focus / C-class datasets do not include road tax / MPG)
Price was the (continuous) feature I wanted to predict, so I knew this was a regression problem. Because I already had sample prices values for my data, I knew I would need a supervised learning algorithm. While it may not be in the hundreds, 9 initial features (which transformed to 41 features once one-hot-encoded) meant that I needed an algorithm that performs well in high-dimensional space. Lastly, used car data was characteristically noisy (two identical cars could have vastly different prices), meaning I needed an algorithm that works well with non-linearly seperable data.
Initial algorithm considerations included clustering, ensemble learning, bayesian methods, and support-vector-machine (SVM) for this project, but clustering was unsupervised. Ensemble learning was a posibility but I felt uncomfortable working with a high-dimensional kernel function if I did not need to (such as with SVM). Bayesian methods were probabilistic by nature, which I preferred less to the deterministic nature of SVM. I chose SVM because it fit well with the data characteristics I had.
For an error / accuracy metric, I used Mean-Absolute-Percentage-Error (MAPE). Typically mean-absolute-error (MAE) and MAPE are used as continuous measures to evaluate a model's effectiveness, but price values had a naturally high magnitude and variance. Naturally it seemed easier to visualize an average ~10% error, than an average 4,000 Euro error (for a 5,000 Euro car, being 4,000 off the average would be a large discrepancy. 4,000 off a 100,000 euro car would be less so). SVM has a few different kernels (modes) one can utilize; since my goal was to minimize residuals (difference between prediction and actual price), I used a linear kernel because it outperformed rbf / poly.
The initial model for my class submission only trained / tested on the Mercedes data and had 85% accuracy, which is pretty good. The dataset was noisy, so it was difficult to make a more accurate model. Evolving the project from my submission, I chose to train / test on all datasets individually, then to create a grand model that trained / tested on all of the combined data (>140 features). Additionally, I performed outlier-processing to remove 2% of the datapoints (≤1%-percentile and >99%-percentile price), which threw off the model accuracy (one car was priced in the seven figures). Afterwards, all models were more accurate (86-88%).